Why do we need Parallel computing?
Why do we need Parallel computing?
Why Parallelism
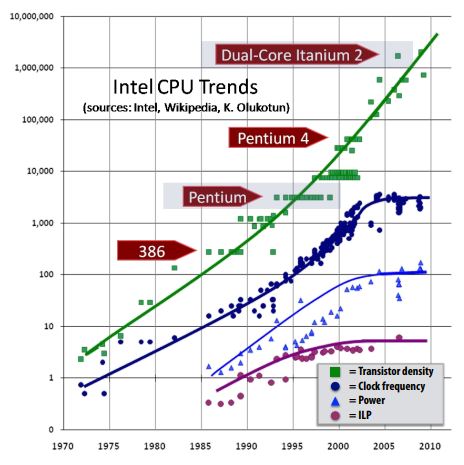
According to the Moore’s Law, the number of transistors on microchips doubles every 2 years. With the smaller transistors, we can have more components on the same area and higher clock frequency. With more components (e.g. ALUs), we may execute more instruction simutanuously if these instructions are independent from each other. They call this Instruction-level parallelism (ILP). On the other hand, higher clock frequency gives us less time to execute one instruction. Based on two above benefits, people used to say that: “We don’t need to do anything. Our program will run faster next year!”
However, sadly, this statement is not true anymore. As shown the figure, there is no further benefit from ILP since 2000. There is not much parallelism at the instruction-level because the instructions are usually related and dependent in locality. The figure also illustrates the problem with clock rate as well. The clock rate stops since 2005, probably at 4GHz. This is due to the power consumed by a transistor. We know that the higher the clock frequency is, the more power is consumed. Power is a critical design constraint in modern processors. A NVIDIA RTX 4090 GPU has the TDP of 450W, half of the TDP of the standard microwave oven.
Because the frequency scaling is limited by power and ILP scaling is tapped out, there are no more free lunch for software developers. We cannot leave it to the Moore’s Law. Software must be written to be parallel to see performance gains.
Multicore Architecture
A basic processor consists of 3 main components:
- Fetch/Decode: determine what instruction to run next.
- ALU (Execution Unit): performs the operation described by an instruction, which may modify values in the processor’s registers or the computer’s memory.
- Registers: maintain program state store value of variables used as inputs and outputs to operations.
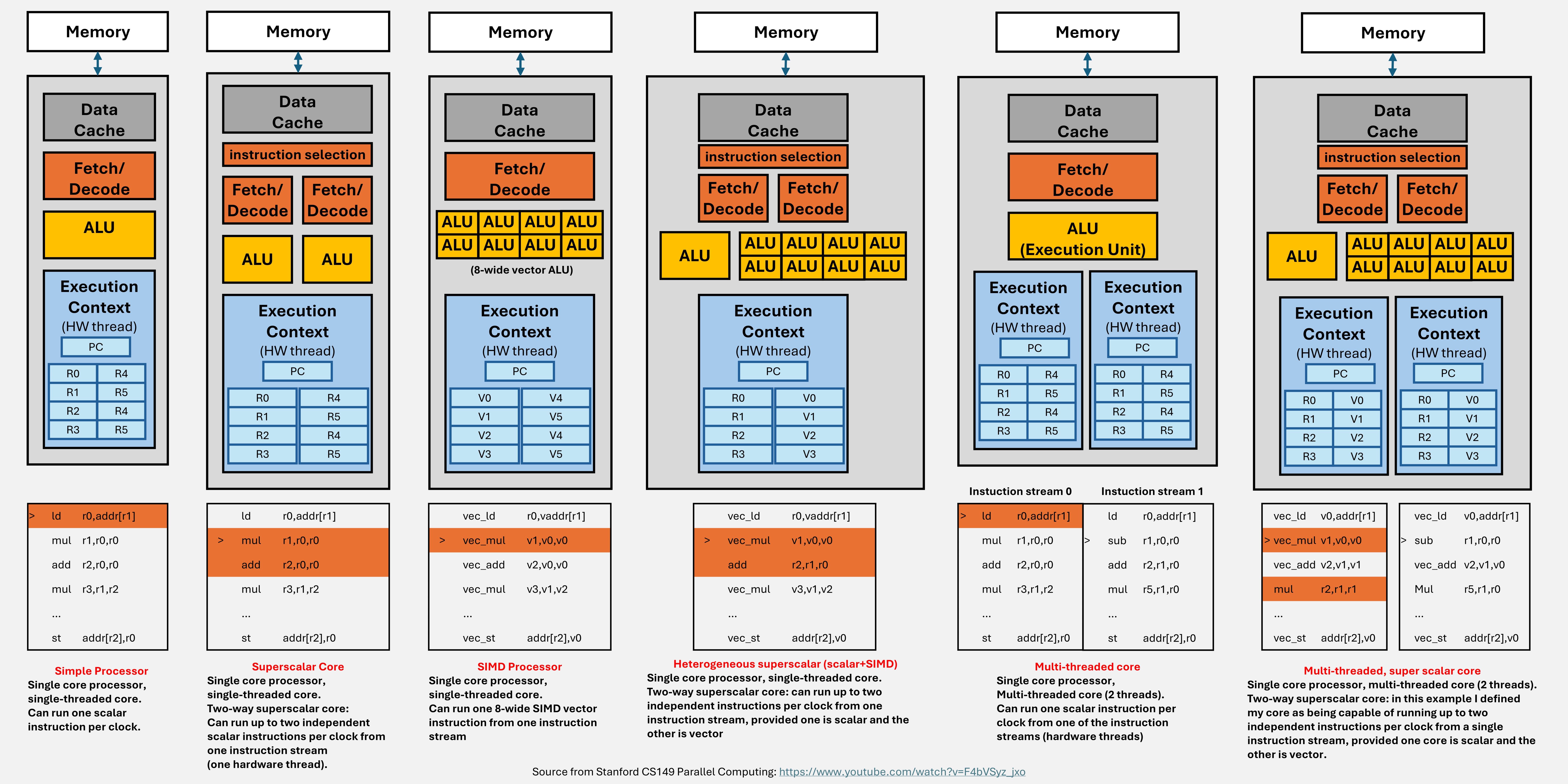
The figure below showed some possible paradigms in which a CPU can be designed.
- Simple processor: executes one instruction per clock.
- Superscalar core: figures out the dependency at instruction level and execute independent instructions in parallel.
- SIMD processor (single-instruction multiple-data): execute one instruction with multiple data (vector-wise operators).
- Heterogeneous superscalar (scalar+SIMD): execute multiple instructions in parallel given they are either scalar or vecter instructions.
- Multi-threaded core: run one instruction at a time from one of the instruction streams (hardware threads).
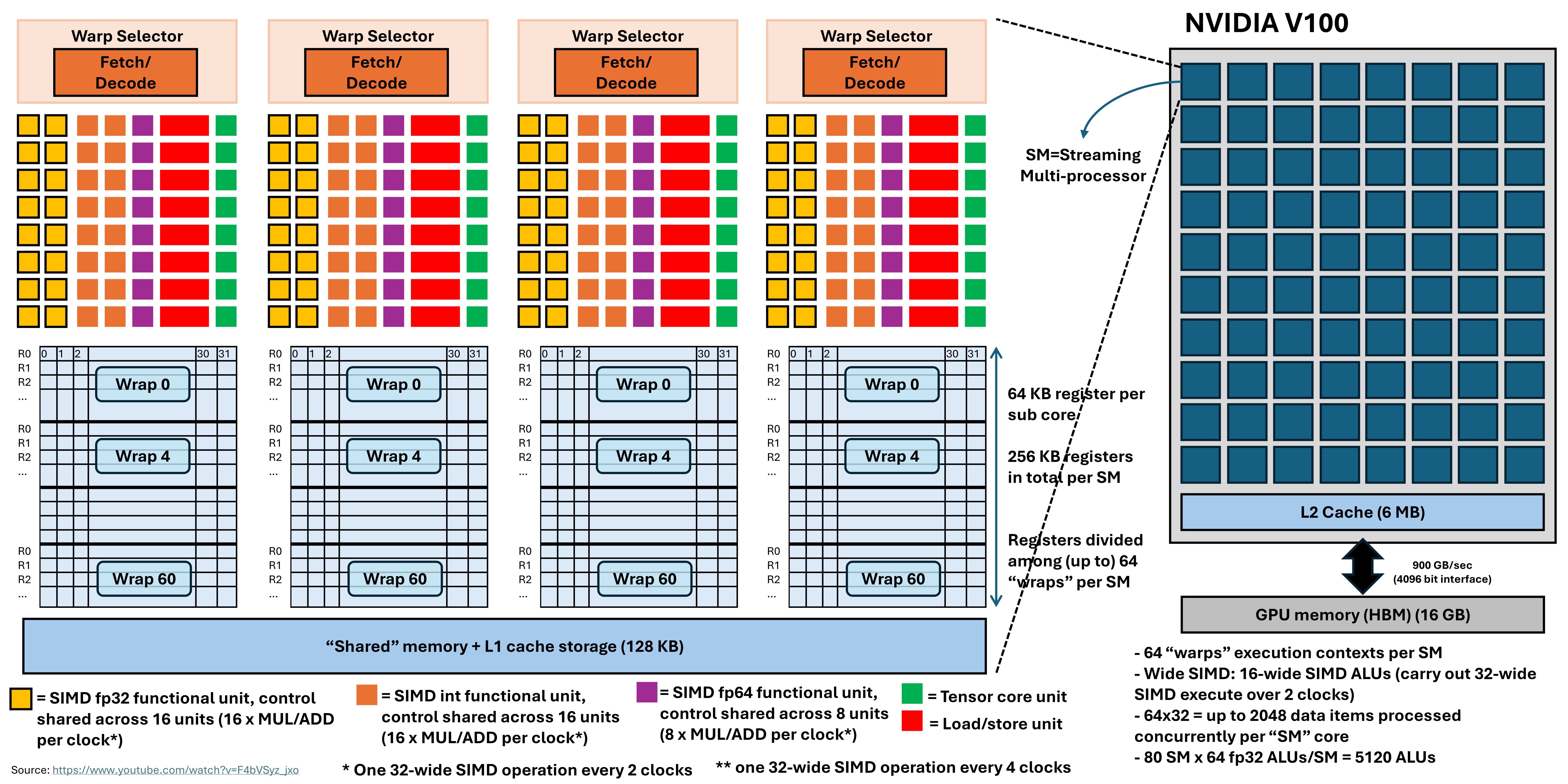
Here is some examples of CPU/GPU architecture design:
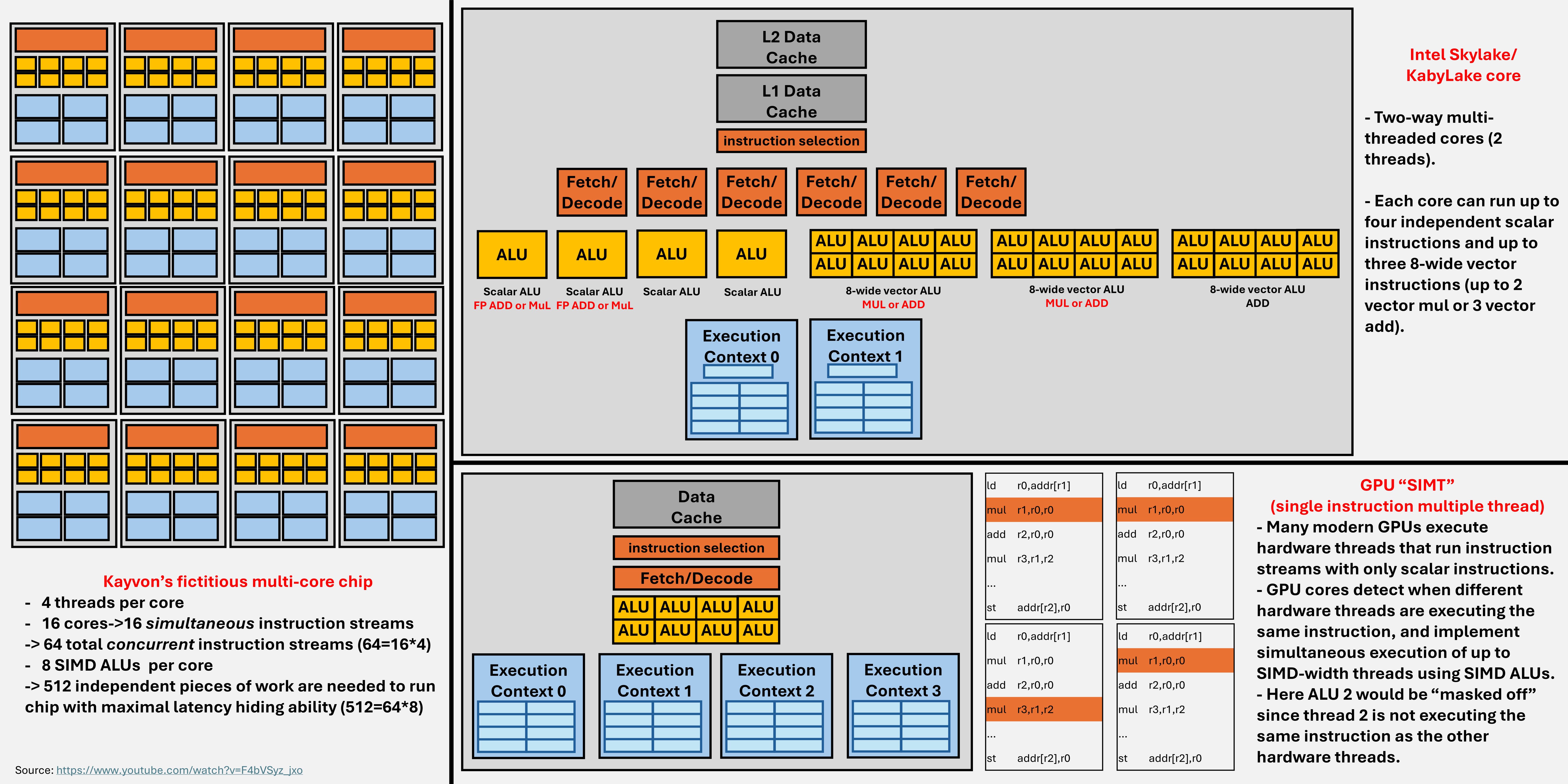
At a high level, these paradigms can be applied for both CPUs and GPUs. As a software engineer, I don’t see many differences between CPUs and GPUs or other hardware accelerators, except that the CPU is equipped with more “intelligent” components (e.g. control flow, branch instructions).
Deep Neural Network Evaluation
To be continue…