Multimodal Bottleneck Transformer for Depression Recognition
Multimodal Bottleneck Transformer for Depression Recognition
Introduction
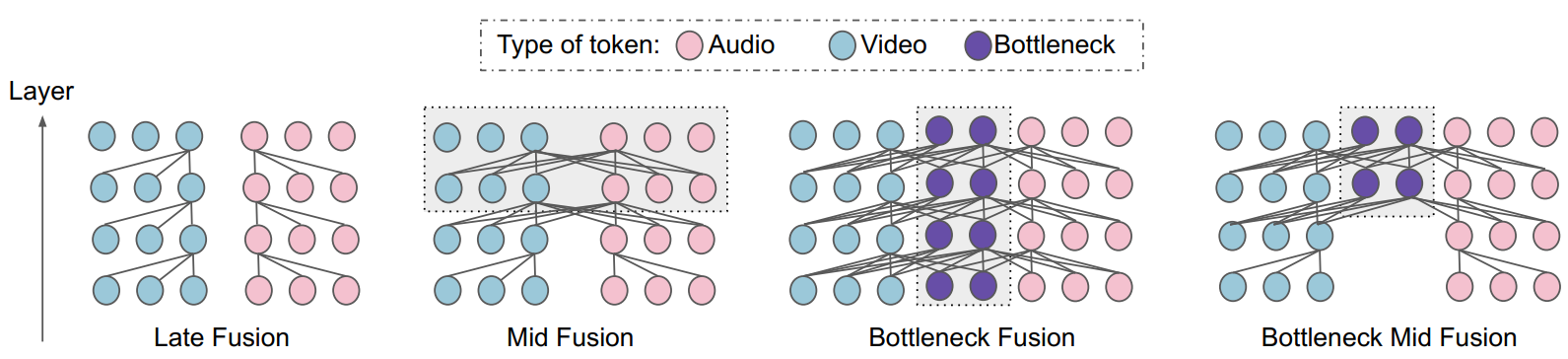
Google Researchers introduces a transformer-based fusion model named Multimodal Bottleneck Transformer (MBT) for fusing visual and audio features. Traditional methods try to concatenate the sequences of two or more embeddings from different modalities in temporal dimension. It consumes a lot of resources (time, memory, and computation) due to the quaradtic complexity of attention mechanism. MBT devises a new special token named bottleneck tokens. It is intermediary token to transfer information between two modalities, instead of paying attention to the whole concatenated sequence.
Implementation
My implementation uses Pytorch framework. Some code from Annotated Transformer is borrowed. Some functions are imported from timm
Define a MBT module
The model includes 2 projection layers, 2 encoder layer groups corresponding to 2 modalities.
class MBT(nn.Module):
def __init__(self, v_dim, a_dim, embed_dim, num_bottle_token=4, bottle_layer=1
, project_type='minimal', num_head=8, drop=.1, num_layers=4, feat_dim=128):
super().__init__()
self.num_layers = num_layers
self.bottle_layer = bottle_layer
self.num_bottle_token = num_bottle_token
self.project_type_conv1d = (project_type=='conv1d')
self.audio_prj = get_projection(a_dim, embed_dim, project_type)
self.video_prj = get_projection(v_dim, embed_dim, project_type)
ff = embed_dim
layer = EncoderLayer(embed_dim, num_head, ff, drop)
self.video_layers = clones(layer, num_layers)
self.audio_layers = clones(layer, num_layers)
self.mask_cls = nn.Parameter(torch.ones(1, 1))
self.mask_bot = nn.Parameter(torch.ones(1, num_bottle_token))
self.bot_token = nn.Parameter(torch.zeros(1, num_bottle_token, embed_dim))
self.acls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.vcls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.norma = LayerNorm(layer.size)
self.normv = LayerNorm(layer.size)
self.head = nn.Linear(embed_dim, feat_dim)
trunc_normal_(self.bot_token, std=.02)
trunc_normal_(self.acls_token, std=.02)
trunc_normal_(self.vcls_token, std=.02)
Define a forward function
def forward(self, a, v, m):
'''
a : (batch_size, seq_len, a_dim)
v : (batch_size, seq_len, v_dim)
'''
B = a.shape[0]
if self.project_type_conv1d:
a = self.audio_prj(a.transpose(1, 2)).transpose(1, 2)
v = self.video_prj(v.transpose(1, 2)).transpose(1, 2)
else:
a = self.audio_prj(a)
v = self.video_prj(v)
acls_tokens = self.acls_token.expand(B, -1, -1)
a = torch.cat((acls_tokens, a), dim=1)
vcls_tokens = self.vcls_token.expand(B, -1, -1)
v = torch.cat((vcls_tokens, v), dim=1)
mask_cls = self.mask_cls.expand(B, -1)
mask = torch.cat((mask_cls, m), dim=1)
for i in range(self.bottle_layer):
v = self.video_layers[i](v, mask)
a = self.audio_layers[i](a, mask)
mask_bot = self.mask_bot.expand(B, -1)
mask = torch.cat((mask_bot, mask), dim=1)
bot_token = self.bot_token.expand(B, -1, -1)
for i in range(self.bottle_layer, self.num_layers):
a = torch.cat((bot_token, a), dim=1)
v = torch.cat((bot_token, v), dim=1)
v = self.video_layers[i](v, mask)
a = self.audio_layers[i](a, mask)
bot_token = (a[:, :self.num_bottle_token] + v[:, :self.num_bottle_token]) / 2
a = a[:, self.num_bottle_token:]
v = v[:, self.num_bottle_token:]
a = self.norma(a)
v = self.normv(v)
feat = (a[:, 0] + v[:, 0]) / 2
return feat