Pretrained Language Model for Emotion Recognition in Korean Conversation
Pretrained Language Model for Emotion Recognition in Korean Conversation
Introduction
The 4th Korean Emotion Recognition International Challenge (KERC22) aims to solve the prolem of Socio-behavior in Korean Conversation. The data is collected from transcript of Korean drama. Each utterance in the conversation is labeled as “dysphoria”, “euphoria”, or “neutral”.
I (CNU_Sclab Team) paticipated in the competition and achieved 4th prize. I use pre-trained language model (particularly, electra) to analyze the conversation context and the speakers’ memory. The detailed solution is described in my paper MAnalyzing Context and Speaker Memory using Pretrained Language Model for Emotion Recognition in Korean Conversation task. The paper is in proceeding of The 10th International Conference on Big Data Applications and Services (BIGDAS22).
I used language model pre-trained on Korean language task from Kim. The idea is inspired the CoMPM model of Lee.
Model Architecture
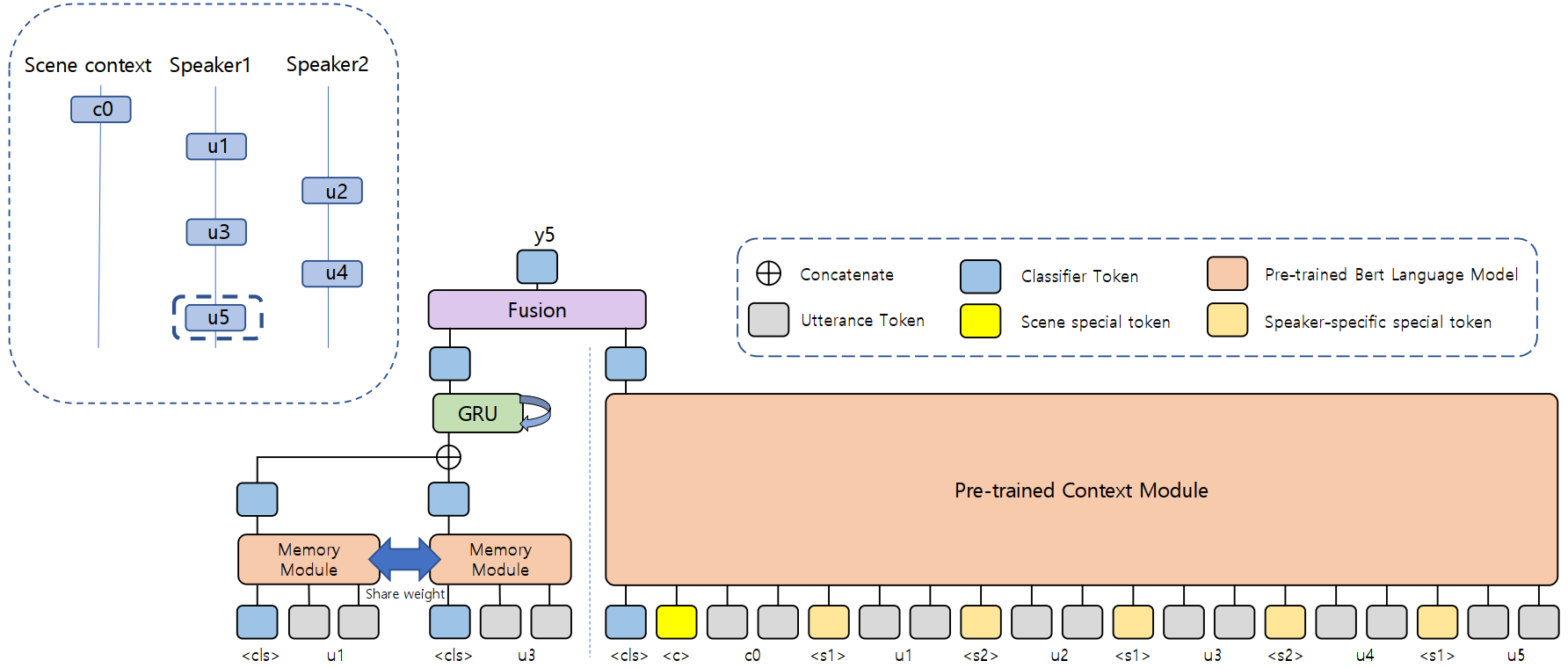
Results
The best performances on validation set of the HUME-VB dataset are listed below:
| Model | F1-score |
|---|---|
| Baseline | 65.67 |
| Emotionflow | 66.88 |
| Ours (Kobert) | 75.33 |
| Ours (Elektra) | 76.50 |